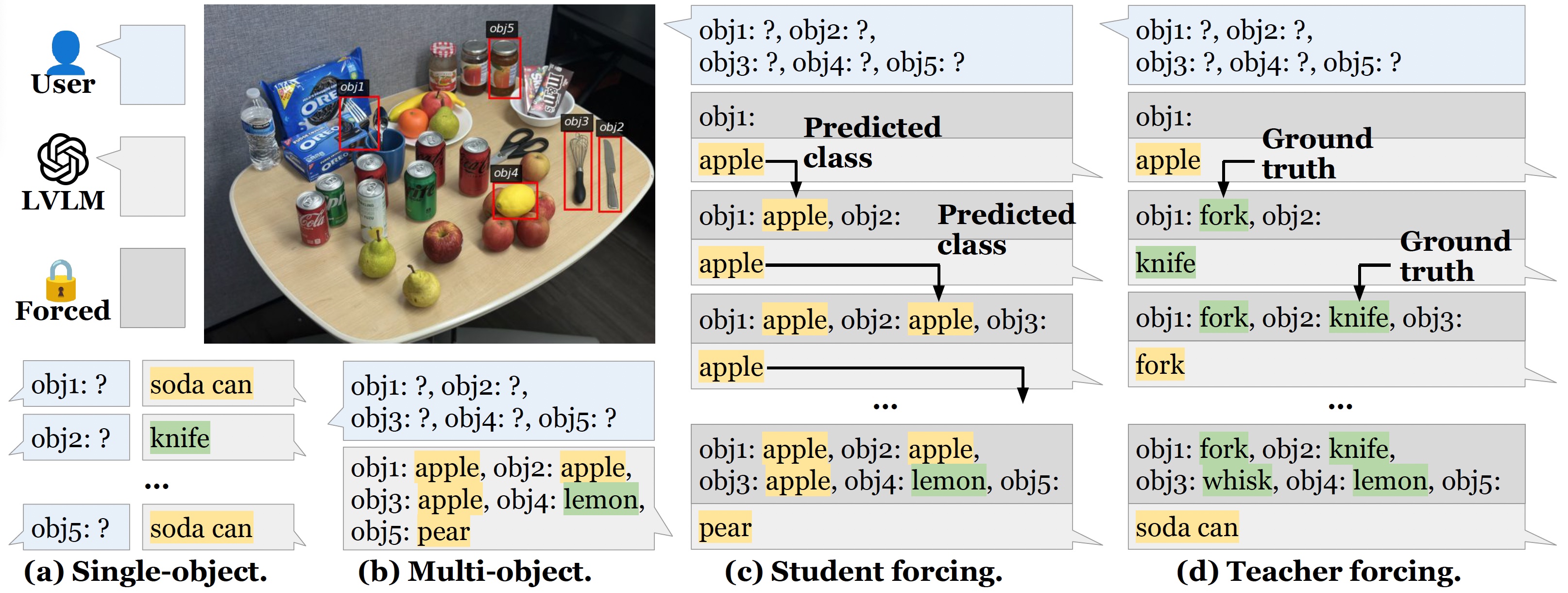
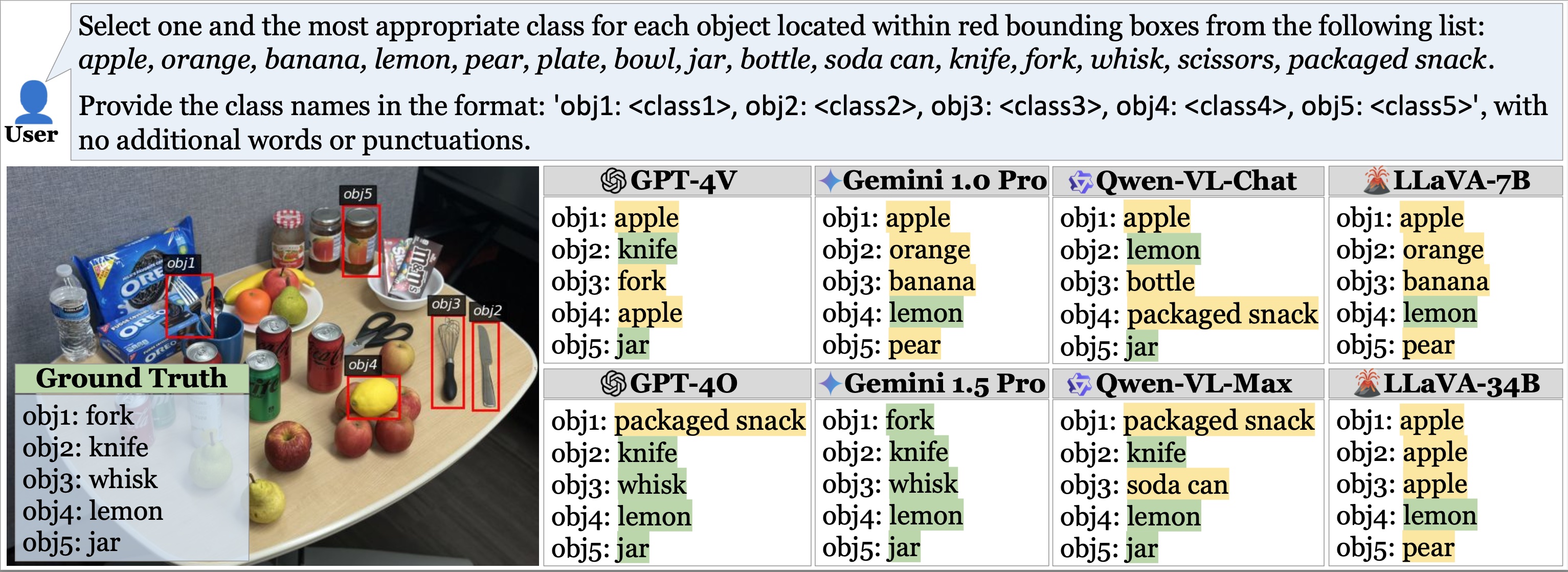
Case Study: Comparing ROPE with Existing Benchmarks
A case study that compares our Recognition-based Object Probing Evaluation (ROPE) benchmark with existing benchmarks for object hallucination in GPT-4V. ROPE offers an automated evaluation protocol with controlled output formatting and uses visual prompts to distinctly ground to objects, thus mitigating referential ambiguity. Unlike binary inquiries relying solely on textual descriptions, ROPE challenges the model to identify multiple objects concurrently. We observe that, while GPT-4V can identify the whisk to the left of a knife when prompted about it, the model hallucinates a "fork" when directly tasked to recognize multiple objects.